Hadoop 集群配置
下半学期开了“大数据与云计算”的课程,一次实验课要求配置 Hadoop 分布式集群。配环境这东西真的不好说,运气好一气呵成,运气不好,真的要杠上两三天。所以这篇就给踩的坑做一个笔记。
前言
Hadoop 提供 单机模式 、伪分布式模式 以及 分布式模式,因为真正的生产环境都是在真正的分布式环境下,所以这里就选最后一种进行配置。
为了方便起见,所有都机器都是本地 CentOS 7 的虚拟机,也只配置一个 master 和一个 worker 节点。
修改主机名
为了方便管理,需要修改一些主机名。
修改 /etc/hosts:
# 增加下面两行
10.211.55.19 master
10.211.55.23 workermaster 就是当前正在配置的虚拟机的内网 IP,worker 准备从 master 里 clone 出来,后续需要再进行补充/修改,到时就不再赘述了。
修改 /etc/hostname:
# 整个替换文件内容,如果是 worker 就填 worker,这一行也不能要
master安装 JDK
Hadoop 是 Java 编写的,所以环境就只用配置 JDK 就好,其它的 CentOS 7 都自带了。
sudo yum install java-1.8.0-openjdk-devel这里一定要安装带 -devel 后缀的 JDK,不然安装的就是 JRE 了,后续还要使用 JDK 的 JPS 工具查看进程是不是如期启动了。版本就安装 8,更高带版本会因为一些模块移除导致各种问题。
echo export JAVA_HOME=/usr/lib/jvm/jre >> ~/.zshrc用的 zsh,其它的根据自己情况更改
安装 Hadoop
我们安装最新的 Hadoop 3.1.1:
wget https://www-eu.apache.org/dist/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
tar -zxvf hadoop-3.1.1.tar.gz
sudo mv hadoop-3.1.1 /usr/local/hadoop然后配置一下环境变量:
echo export HADOOP_HOME=/usr/local/hadoop >> ~/.zshrc
echo export HADOOP_COMMON_HOME=$HADOOP_HOME >> ~/.zshrc
echo export HADOOP_HDFS_HOME=$HADOOP_HOME >> ~/.zshrc
echo export HADOOP_YARN_HOME=$HADOOP_HOME >> ~/.zshrc
echo export HADOOP_MAPRED_HOME=$HADOOP_HOME >> ~/.zshrc
echo export HADOOP_INSTALL=$HADOOP_HOME >> ~/.zshrc
echo export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native >> ~/.zshrc
source ~/.zshrcHADOOP_HOME 是一定要配,绝大多数博客也都说了,剩下的很少有文章提到,但是启动的时候就会提示没有配置而启动失败。
配置 Hadoop
etc/hadoop 目录下是 Hadoop 的配置文件,暂时只需要关注 hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml 和 yarn-site.xml 这五个文件。
注意现在是在 master 节点上配置
hadoop-env.sh
这个文件是 Hadoop 启动时的环境配置文件,不知道为什么还要把 JAVA_HOME 在这个文件里再写一遍,反正不写会启动失败:
echo export JAVA_HOME=/usr/lib/jvm/jre >> $HADOOP_HOME/etc/hadoop/hadoop-env.shcore-site.xml
这个文件配置集群全局参数,如 HDFS URL、Hadoop 临时目录等。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 配置 HDFS URL,这里 master 需要在 /etc/hosts 里配置 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 配置 Hadoop 临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///home/centos/hadoop</value>
</property>
<!-- 这里配置 WebUI 登陆的用户,当前虚拟机用户名是 centos,用户名就代表了操作权限,默认用户是 read-only 权限 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>centos</value>
</property>
</configuration>hdfs-site.xml
这个文件配置 HDFS 参数,namenode、datanode 数据存储位置,文件副本数量等。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 文件副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- namenode 数据存储位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/centos/hadoop/dfs/name</value>
</property>
<!-- datanode 数据存储位置 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/centos/hadoop/dfs/data</value>
</property>
</configuration>mapred-site.xml
Mapreduce 配置文件。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 使用的框架,计算任务会由 yarn 提供计算资源解决 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
配置 yarn (资源管理)参数,如 ResourceManager、NodeManager 通信端口,WebUI 端口等。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>配置子节点
到这里主节点就配置完成了,通过 clone 虚拟机完成子节点的创建,然后简单修改 /etc/hosts 文件就可以了。
然后再修改 主节点 上的 $HADOOP_HOME/etc/hadoop/workers,没有就创建:
hadoop@worker
# 一排一个子节点这里的 Hadoop 是子节点的用户名,worker 之前在 /etc/hosts 里配置了。
网上文章一般都是只填 worker,而不填前面的用户名 这是因为一般情况下所有节点都应该配置成一样,比如用户名、目录等,方便管理减少配置成本。但是有时候主节点和子节点的用户名不一样,比如主节点用户名叫 centos,那么在主节点执行
ssh worker等价于执行ssh centos@worker。当然为了避免麻烦,使用统一的配置才是正解。
启动
第一次启动 之前在主节点上执行:
$HADOOP_HOME/bin/hdfs namenode -format在 主节点上 依次执行:
# 启动 HDFS
$HADOOP_HOME/sbin/start-dfs.sh
# 启动 yarn
$HADOOP_HOME/sbin/start-yarn.sh
# 启动 historyserver
$HADOOP_HOME/bin/mapred --daemon start historyserver判断有没有启动成功可以 jps 查看 Java 进程:
10848 JobHistoryServer
10289 SecondaryNameNode
10515 ResourceManager
10061 NameNode
10910 Jps
在 子节点 上执行 jps 会看到:
4626 DataNode
4859 NodeManager
4950 Jps如果想关闭的话,在主节点上执行:
$HADOOP_HOME/sbin/stop-dfs.sh
$HADOOP_HOME/sbin/stop-yarn.sh
$HADOOP_HOME/bin/mapred --daemon stop historyserverWeb UI
启动完 hadoop 之后,访问 http://10.211.55.19:9870
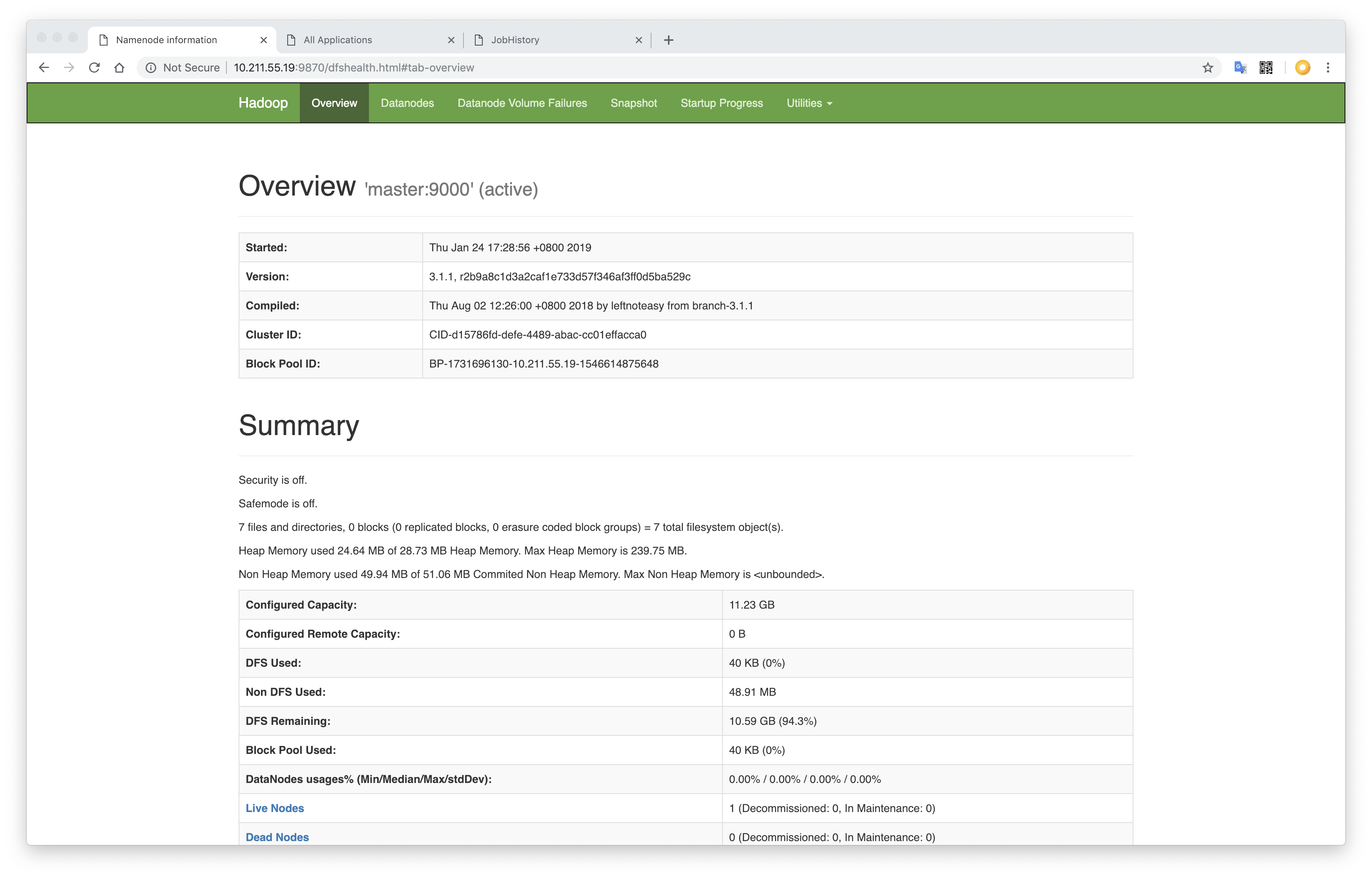
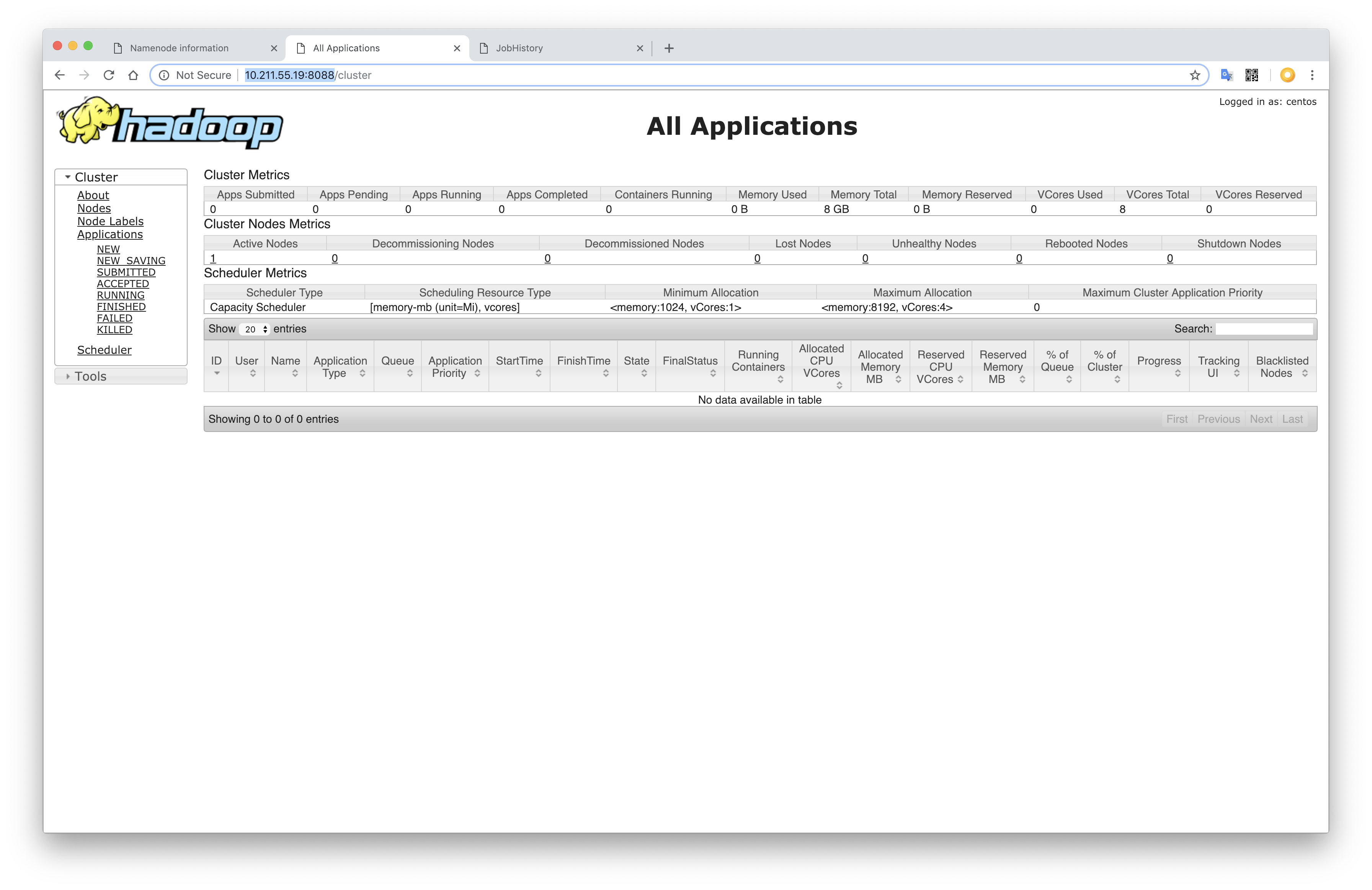
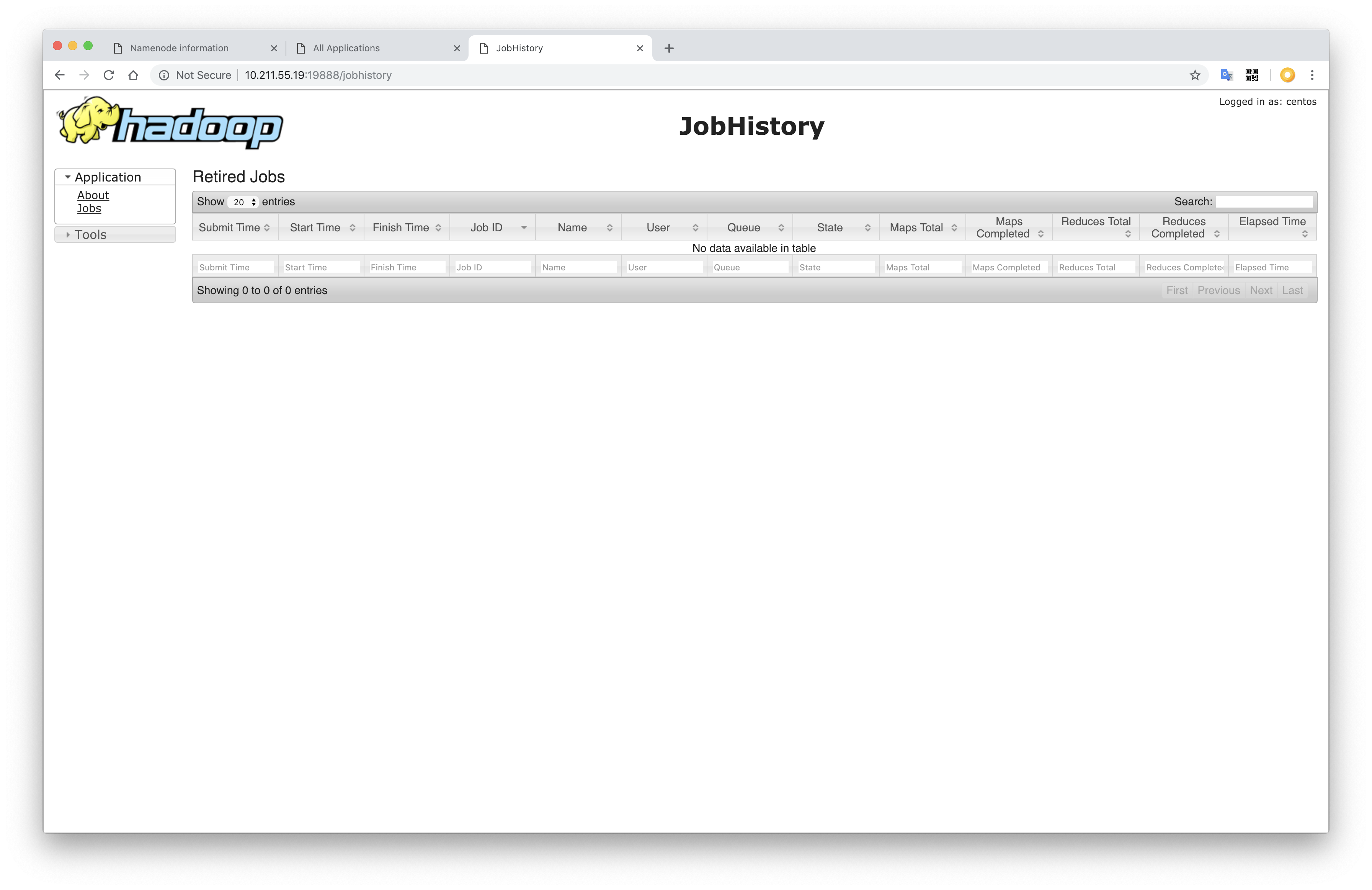
References
2026-06-01
写于 2019 年,基于 Hadoop 3.1.1 / CentOS 7 / Java 8。Hadoop 当前已演进至 3.3.x 及更新版本,CentOS 7 已于 2024 年 EOL,Java 8 趋于老旧。集群配置方式基本稳定,但版本与环境信息已过时,新项目建议参考官方最新文档。